
¿Qué son los datasets?
Un dataset es una colección estructurada de datos, reúne información sobre un conjunto de casos organizados mediante la intersección de una o más dimensiones. Es la base sobre la cual se construirán las visualizaciones.
En su configuración general se conjugan distintos elementos: información cualitativa y especificaciones (por ejemplo nombre, descripción y fórmula de cálculo), funcionalidades que van a estar disponibles en su visualización (por ejemplo valores porcentuales, agregación de datos) y la construcción de la estructura de datos que adoptará el mismo, definida por una o más dimensiones.
Todos estos elementos se encuentran organizados en campos administrables que son detallados a continuación.
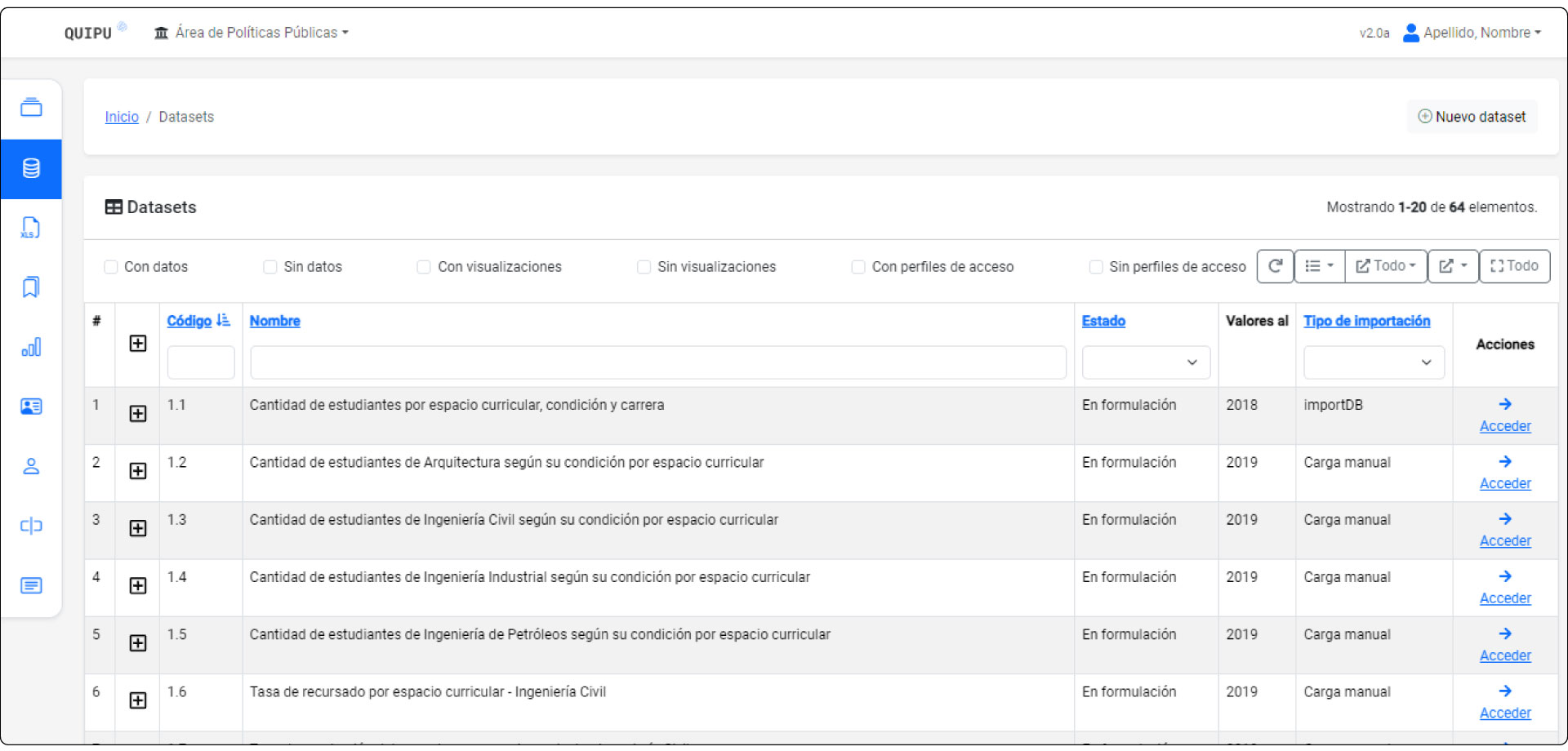
Sección Datasets en el Administrador
¿Qué se necesita para generar un dataset?
Al ingresar a la Sección Datasets y seleccionar "Nuevo dataset", el sistema presenta todos los campos que se deben completar para configurar un dataset.
A continuación se describe cada uno de los campos disponibles.
Descripción de campos
Nombre
Es la denominación que tendrá el dataset en el Administrador del sistema. El mismo no será visible en el Visualizador. Es un campo de texto abierto en el que se recomienda escribir de manera sintética, incorporar las dimensiones incluidas, colocar mayúscula solo en la primera letra de la oración, y no colocar punto al final.
Es un campo obligatorio.
Código
Combinación de caracteres alfanuméricos que utilizarán los administradores para la identificación de los datasets. Este código debe ser único. Es un campo de texto abierto en el que se recomienda utilizar las iniciales de las áreas o dependencias generadoras de los datos, y numerar de manera incremental para obtener un listado que ordene y oriente la búsqueda de la información.
Es un campo obligatorio.
Estado
Etapa del proceso de configuración en que se encuentra el dataset. Los estados permiten la organización de los datasets en conjuntos que ayudan a la administración de la plataforma. Los mismos no son visibles en el Visualizador.
Es un campo obligatorio que por defecto se encontrará marcado en el primer estado del listado que haya sido configurado.
Tipo de importación
Se refiere al mecanismo por el cual se efectúa la carga y actualización de datos de un dataset. Puede ser realizado por un usuario del sistema o por un procedimiento automatizado. Las opciones que ofrece el sistema son las que se encuentran cargadas en el apartado Tipos de importación.
Es un campo obligatorio que por defecto se encuentra marcado en el primero disponible.
Para mayor información visitar Tipos de importación
Valores porcentuales
En el caso de que el dataset tenga datos porcentuales se debe marcar “Si”. Esto le indica al sistema que restrinja una serie de funcionalidades en la presentación del gráfico en el Visualizador.
Advertencia: Si se marca “Si” el sistema deshabilitará la agregación de datos de manera automática.
Deshabilitar agregar datos
Se debe marcar "Si" cuando no desee permitir la agregación y sumarización de datos en el Visualizador.
La misma debe ser utilizada en el caso que los datos del dataset no deban ser sumarizados ni agregados. Por defecto el sistema deja deshabilitada esta opción pudiendo habilitarla cuando sea pertinente.
Advertencia: Esta opción se seleccionará automáticamente y no podrá modificarse si está marcado “Si” en el campo Valores porcentuales.
Deshabilitar la desagregación de datos tiene dos implicancias. Por un lado, al momento del filtrado de las dimensiones para crear una visualización desde el Administrador no se podrá destildar dimensiones completas. Por otro lado, al personalizar gráfico o tabla en el Visualizador, tampoco será posible destildar dimensiones completas. Esto se debe a que para quitar/destildar dimensiones completas, los datos deben agregarse y sumarse en las dimensiones restantes.
Para más información sobre el filtrado de las dimensiones para crear una visualización visitar Creación y configuración de visualizaciones
¿Cuándo es pertinente deshabilitar la agregación?
Como criterio general la agregación de datos no es válida para los datasets que contienen valores expresados en términos porcentuales o de promedio, dado que los porcentajes y promedios no se suman. Por ejemplo, en caso del dataset de ejecución presupuestaria acumulada mensual, habilitar la agregación no sería adecuada dado que se estarían sumando valores que ya están considerados en los meses anteriores.
Dado que la máxima agregación temporal es anual (el sistema no permite hacer acumulados bienales, trienales, etc.), para los datasets nominales que son anuales en general no es necesario deshabilitar la función de agregación. Ello permitirá conservar la acción de acumular para las otras variables distintas de la temporal.
Unidad de medida
Es un campo de texto abierto que se utiliza para consignar la unidad en que están expresados los datos del dataset. La misma estará disponible en el Visualizador, tanto en la tarjeta como en la ficha técnica de cada visualización que se genere a partir del dataset.
Las unidades de medida son tamaños de referencia que se acuerdan para medir distintas magnitudes, son necesarias para medir, describir y comprender cada dataset. Ejemplo: porcentaje, pesos corrientes, cantidad.
Es un campo obligatorio.
Área productora de datos
Es un campo de texto abierto que se utiliza para consignar el área o dependencia responsable de los datos contenidos en el dataset. Esta información estará presente en el Visualizador, en la ficha técnica de cada visualización que se genere a partir del dataset.
Funcionario/s responsable/s
Es un campo de texto abierto que se utiliza para consignar la o las personas responsables por la publicación de los datos contenidos en el dataset, que no necesariamente es la persona que realiza la carga de los datos en el sistema.
Esta información estará disponible en el Visualizador, en la ficha técnica de cada visualización que se genere a partir del dataset.
Descripción
Es un campo de texto abierto en el que se debe consignar de manera clara qué información es la que contiene el dataset. Permite agregar información, notas técnicas o aclaratorias sobre los datos, necesarias para su comprensión.
Este texto estará presente en el Visualizador, en la ficha técnica de cada visualización que se genera a partir del dataset.
Al momento de configurar cada visualización el sistema permite editar el texto de la descripción en caso de ser necesario, para ajustarlo a los filtros que se definen en cada una.
Forma de cálculo
Es un campo de texto abierto donde se deberá expresar por escrito la fórmula y/o operaciones que se han efectuado para obtener los datos, para facilitar su comprensión.
Este texto estará presente en el Visualizador, en la ficha técnica de cada visualización que se genera a partir del dataset.
Al momento de configurar cada visualización el sistema permite editar el texto de la forma de cálculo en caso de ser necesario, para ajustarlo a los filtros que se definen en cada una.
Sql Import
Este campo solo se utiliza cuando el Tipo de importación corresponde a "Conexión con base de datos". Aquí es posible incluir una consulta SQL personalizada que será ejecutada por la rutina de importación de datos.
Estructura de datos
En este campo se deben agregar las dimensiones que conforman el dataset.
La estructura de datos define el formato que deben cumplir los datos que se pretenda guardar en el dataset. La misma está compuesta por la combinación de dimensiones temporales y adicionales.
La dimensión Año se asocia automáticamente a todos los indicadores. Opcionalmente, es posible agregar las siguientes dimensiones:
-
Dimensiones temporales sub anuales: mes, bimestre, trimestre, cuatrimestre o semestre.
-
Dimensiones adicionales: son aquellas que han sido creadas por los usuarios desde la sección “Dimensiones”. El sistema presenta un listado desplegable, en este campo se podrá seleccionar una o más dimensiones.
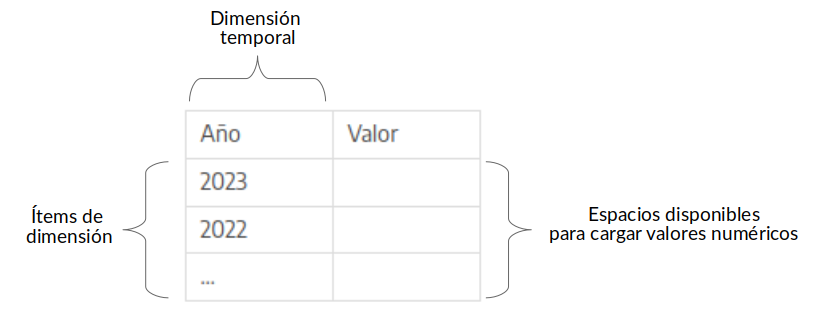
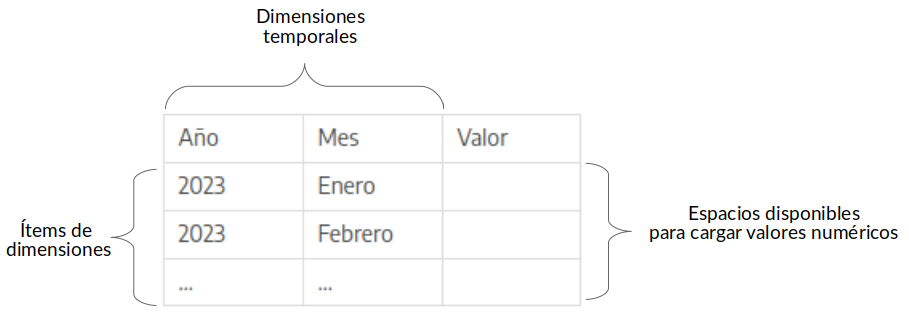
Como puede observarse en los ejemplos que se muestran a continuación, el sistema permitirá cargar datos de acuerdo a las dimensiones que se han seleccionado teniendo en cuenta los ítems agregados en las mismas. Se genera una matriz con la combinatoria de ítems que luego permitirá asociar un valor numérico por cada combinación.
Ejemplos
Periodicidad anual sin otras dimensiones:
 Periodicidad mensual (dimensión sub-anual) sin otras dimensiones:
Periodicidad mensual (dimensión sub-anual) sin otras dimensiones:
Periodicidad anual con dimensión adicional (ej: franja etaria).

Recomendación: si bien el sistema no establece límites, es recomendable no utilizar más de 4 dimensiones (entre temporales y adicionales) por dataset. Mayor cantidad de dimensiones podría generar gráficos y tablas demasiado complejos, que resultarán de difícil configuración e interpretación por parte de los usuarios de lectura.
Definida la estructura de datos de un dataset, el sistema permitirá incorporar datos de acuerdo a la misma. Una vez que se haya cargado al menos un valor en la base de datos esta estructura no podrá modificarse hasta tanto se eliminen todos los datos cargados.
Conceder acceso de lectura a los perfiles seleccionados
Este campo permite seleccionar los perfiles que tendrán permiso de lectura o acceso en el Visualizador a todas las visualizaciones creadas a partir del dataset.
La asociación de un dataset a un perfil de acceso también puede realizarse luego de la creación del dataset, editando el/los perfil/es de acceso. Para más información visitar Creación, edición y eliminación de perfiles de acceso a datasets - Editar perfiles
Para más información sobre Perfiles de acceso a datasets visitar ¿Qué son los perfiles de acceso a datasets? o Guía práctica de perfiles de acceso a datasets
Si un dataset no está asociado a uno o más perfiles de acceso, las visualizaciones creadas a partir de este no estarán disponibles en el Visualizador para los usuarios con Rol de Lectura.
Es importante completar correctamente estos datos porque gran parte de ellos se utilizarán para el armado de las fichas técnicas que acompañan las visualizaciones que se crean a partir de cada dataset.